
A lot of people think that GraphQL is for Front End and JavaScript only, that it doesn’t have the place with Backend technologies like Java, but is that really the case.
Also very often GraphQL is compared to REST, but is this comparison justified one or not?
First, let me start by answering the most important question of them all. What is GraphQL?
If you check official website you will see something like this
“GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. GraphQL isn’t tied to any specific database or storage engine and is instead backed by your existing code and data.”
What actually it should say is
GraphQL is a specification, nothing more and nothing less.
This is an important thing to remember since we as developers will be working with implementations of GraphQL. Some of the implementations have implemented more or less of things from GraphQL specification. There are implementations in many languages like JavaScript, Java, PHP, Go and others. There are new implementations being made every day in different languages and in existing ones.
If you are coming from Java background and have made a fair deal of REST APIs, the first thing that would interest you is how GraphQL differ from Traditional REST API that you have been developing over the years.
Let me put that into the context of a simple blog, which consists of blog posts, authors of blog posts, and there is an option of putting comments on blog posts.
From DB point of view, it would mean we have three tables
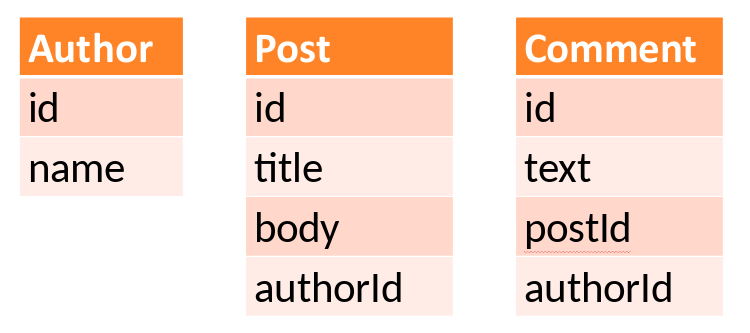
Let us assume, that front end is read only, and get the data from Traditional REST API and then present data to the user. If we were to build this traditional REST API, we would probably end up with some code like this
@RestController
public class SimpleRestController {
@RequestMapping(path="/authors")
public List getAllAuthors() { ... }
@RequestMapping(path="/authors/{id}")
public Author getAuthorById(@PathVariable String id) { ...
}
@RequestMapping(path="/posts")
public List getAllPosts(@RequestParam(value="author_id", required = false) String authId) { ... }
@RequestMapping(path="/comments")
public List getAllComments(@RequestParam(value="post_id", required = false) String postId) { ... }
}
So in this case, if we would like to show a post with author info and comments, we would first need to call
- /posts
to get all posts, then find the post which we want, see what is authorId, then call
- /authours/<id from post>
after which we would need to call
- /comments?post_id=<id of post in question>
to get all comments for that post.
It is obvious that this isn’t the most optimal approach. Of course what all of us would do in this case, would be to look good at use cases for our API and optimize endpoints and responses with that in mind. Perhaps we would embed comments into posts, or author info or something similar. Or maybe we wouldn’t change a thing if we think that this is ok, due to some reason. In any case, we would decide what endpoints user can call, and what kind of response they would get.
Precisely this is the biggest difference when it comes to GraphQL. In case of GraphQL, there is usually only one endpoint, for example
- /graphql
This endpoint will get all requests for your API and send back all responses.
This might sound little strange at first. The easiest way to follow would be to have full code of working example. I will be using snippets of code from one such example. To get full code just hit this URL https://github.com/vladimir-dejanovic/simple-springboot-graphql-mongo-conftalk-demo
The important thing to remember is that in GraphQL everything starts and ends with the schema. If we go to the example above, blog post, GraphQL schema might look something like this:
type Author {
id: ID!
name: String!
posts: [Post]
}
type Post {
id: ID!
title: String!
body: String
createdBy: Author!
comments: [Comment]
}
type Comment {
id: ID!
createdBy: Author!
belongsTo: Post!
text: String
}
schema {
query: Query
}
type Query {
allPosts: [Post]
allAuthors: [Author]
}
We start by defining the types, and types can be almost 1 to 1 with POJO’s that we would create for our tables. First, we put a name, then type. The character ‘!‘ has special meaning, and it means that field is mandatory. If a field has this character and it isn’t present in response it will be an invalid response and GraphQL will not send the response back, but will send appropriate error.
The important thing to remember about schema is that all request and response will be validated with the schema. If a request doesn’t pass schema validation, no work will be done by the server. Also if a response doesn’t pass schema validation, it will not be sent to the client.
If you check type Author you will see that it has field posts which is of type Array of Post. Also, Post has field createdBy of type Author and comments which is of type Array of Comment. These fields are not present in POJO’s
Author.java
public class Author {
private final String id;
private final String name;
.....get/set
}
Post.java
public class Post {
private final String id;
private String authorId;
private final String title;
private final String body;
...get/set
}
The similar thing is with type Comment, I will come back later at this. After we define types we can go to the heart of GraphQL schema
schema {
query: Query
}
This is where we define interaction with the user. We say that user can read data by using the query which is of type Query defined below.
type Query {
allPosts: [Post]
allAuthors: [Author]
}
The Query is a special type since we don’t have this data in DB, this is actually our endpoint in the traditional way of thinking.
If you downloaded code from GitHub link, compiled and started you can go to http://localhost:8080/ . Then you will see nice user interface called GraphiQL. You can use GraphiQL to play with GraphQL API
In order to get all posts with their id, title, and body, just enter this into GraphiQL
query {
allPosts {
id
title
body
}
}
Response should look something like this
{
"data": {
"allPosts": [
{
"id": "59f4c12e7718af0b1e001072",
"title": "Who is Ed Wong",
"body": "Edward Wong Hau Pepelu .....”
},
. . . .
}
if for example, we were not interested in the body we could enter something like this
query {
allPosts {
id
title
}
}
a response would then be like this
{
"data": {
"allPosts": [
{
"id": "59f4c12e7718af0b1e001072",
"title": "Who is Ed Wong",
},
. . . .
}
As you can see, when it comes to the GraphQL user doesn’t get always the same predefined set of fields in the response. The user has the option, to say which fields should be sent back, and which don’t.
Java code which is needed to allow this isn’t that big. First, we need to define Servlet which extends SimpleGraphQLServlet
public class GraphQLEntryPoint extends SimpleGraphQLServlet {
public GraphQLEntryPoint(PostRepository postRepository, AuthorRepository authRepository, CommentRepository commentRepository) {
super(buildSchema(postRepository,
authRepository,
commentRepository));
}
private static GraphQLSchema buildSchema(PostRepository postRepository, AuthorRepository authRepository, CommentRepository commentRepository) {
return SchemaParser
.newParser()
.file("schema.graphqls")
.resolvers(
new Query(postRepository,
authRepository),
new PostResolver(authRepository,
commentRepository),
new AuthorResolver(postRepository),
new CommentResolver(authRepository,
postRepository))
.build()
.makeExecutableSchema();
}
}
Here I create schema parser which opens my GraphQL schema file, after which resolvers are added, and then build and makeExecutableSchema methods are called.
The important part here is resolvers. Resolvers are classes that GraphQL will use in order to resolve user request.
For starters, most important one is class Query. It isn’t a coincidence that it has the same name as type Query in the schema. That is how java GraphQL implementation knows which class corresponds to query logic from the schema. You can use any name you like, as long as the class has the same name like that, however, it will mean that new people will need to know this also, so keep stuff standard, and for Read-Only use Query.
Here is code for class Query
public class Query implements GraphQLRootResolver {
private final PostRepository postRepository;
private final AuthorRepository authRepo;
public List<Post> allPosts() {
return postRepository.findAll();
}
public List<Author> allAuthors() {
return authRepo.findAll();
}
}
It implements GraphQLRootResolver, and as you can see has one method for each line from GraphQL schema.
There is a method called allPost which return a list of Post, and also there is method allAuthors that return a list of Author. This is all that is needed in order for our API to work.
If you go back to GraphiQL and enter input like this
query {
allPosts {
id
title
createdBy {
name
}
}
}
response would be something like this
{
"data": {
"allPosts": [
{
"id": "59f4c12e7718af0b1e001072",
"title": "Who is Ed Wong",
"createdBy": {
"name": "Ed Wong”
}
},
. . .
]
}
you will get all of a sudden data in response which isn’t part of the Post pojo. As we just saw, Query class doesn’t do any magic it just returns a list of plain pojo’s of type Post. So from where does then Author info come from, for field createdBy?
For that we need to look at another resolver, PostResolver to be more precise, so let us look at its code
public class PostResolver implements GraphQLResolver<Post> {
private final AuthorRepository authRepository;
private final CommentRepository commentRepository;
public Author createdBy(Post post) {
return authRepository.findOne(post.getAuthorId());
}
public List<Comment> comments(Post post) {
return commentRepository.findByPostId(post.getId());
}
}
PostResolver implements GraphQLResolver and we have to say for which type, in this case, it is for Post. As you can see all fields from the schema which were present in Post, but not present in Pojo Post are present here as methods. There is method createdBy which takes an argument of type Post and return back Author.
Also, there is method comments which also take an argument of type Post and returns the list of Comment.
That is all there is to it, this is how java implementation of GraphQL that I am using in my code knows how to resolve fields which are not present in pojo’s. In case of pojo, it is very simple, just call appropriate get method if a user requested that field, for other fields there has to be resolver for that type that implements GraphQLResolver and there needs to be a method with correct signature and return type.
As you see for yourself, with GraphQL user is in much more control what data he/she will get and in which format, compared to traditional REST API that we have been creating for all this time. This of course, as a result, has much better user experience, from a user perspective, since there is more flexibility. However, this also means there is much more work that needs to be done in the backend, so that system still performs well under the high load.
In traditional REST API we, as developers, were under full control of how the user will interact with our endpoints, what kind of response they will get, and also which path user request will follow in our code. As we saw, with GraphQL that isn’t the case anymore. What we know is that user will hit resolvers, but not also how or via which path. Due to this, optimization is much harder.
Lucky not all is lost, we can still use a lot of old tricks to solve these new/old problems. If for example, we take traditional REST API, one way of solving the problem of high performance would be to have a controller, with endpoints, calling service, and then the service would do the heavy lifting. In this setup, we could cache all calls to service, and in this easy way get good performance. We can do a similar thing with GraphQL, the only difference would be instead of controllers calling services, we would have resolvers calling services.
Problems might be a little bit more tricky with GraphQL, however, a lot of techniques from the past can be used, in combination with a little bit of thinking. Of course, a lot of new ways of solving problems will appear with every day.
I only showed you here how to read data, you can of course also create/edit/modify data, and do so much more with GraphQL. What I shared with you is just scratching the surface, when it comes to functionalities offered by GraphQL in building APIs.
The important thing that you need to remember is that, although GraphQL is relatively new, all things that it offers, can be achieved also without it. However, in this case, you will need to think what you will allow to your users to do, and how will they send this request to your API. In case of GraphQL someone else already thought about it, and all that you need to do is implement it.
At the end, GraphQL API is REST API, advanced REST API with a lot of features and functionalities to be more precise. That is why, it is a good thing to ask your self, do you really need functionalities that GraphQL is offering, and will it add more problems or solutions to your API and domain for which this API was built. Perhaps GraphQL is precisely what you need, but then again maybe good old traditional REST API is all that you need.
Resources
- Code Example https://github.com/vladimir-dejanovic/simple-springboot-graphql-mongo-conftalk-demo
- GraphQL java implementation https://github.com/graphql-java/graphql-java
- Talk GraphQL vs Traditional REST API at Devoxx Morocco by Vladimir Dejanovic https://www.youtube.com/watch?v=2FH93GaoIto
Author: Vladimir Dejanovic
Founder and leader of AmsterdamJUG.
JavaOne Rock Star, CodeOne Star speaker
Storyteller
Software Architect ,Team Lead and IT Consultant working in industry since 2006 developing high performance software in multiple programming languages and technologies from desktop to mobile and web with high load traffic.
Enjoining developing software mostly in Java and JavaScript, however also wrote fair share of code in Scala, C++, C, PHP, Go, Objective-C, Python, R, Lisp and many others.
Always interested in cool new stuff, Free and Open Source software.
Like giving talks at conferences like JavaOne, Devoxx BE, Devoxx US, Devoxx PL, Devoxx MA, Java Day Istanbul, Java Day Minks, Voxxed Days Bristol, Voxxed Days Bucharest, Voxxed Days Belgrade, Voxxed Days Cluj-Napoca and others
 steinhauer.software
steinhauer.software
Jean SILGA December 27, 2017
Nice artcile. I have been hearing about GraphQL for some time. Now I know what it is and how to implement it in java. Thanks a lot!
In the sentence “In traditional REST API we, as developers, where under full control”, I am wondering if “were” was not intended in lieu of “where”.
Vladimir Dejanovic December 31, 2017 — Post Author
true, thx for spotting this 🙂
Jean SILGA December 27, 2017
I have a question. Given N posts having the same author. Will GraphQL hit the database N times to get the same author with this query?
query {
allPosts {
id
title
createdBy {
name
}
}
}
Vladimir Dejanovic December 31, 2017 — Post Author
It depends from code at hand, and implementation of GraphQL which is used.
In case of simple example that I shared in this post and on GitHub, the answer would be yes, DB would be hit multiple times for same author.
However, this code wasn’t intended for use in production, because of this reason and some others.
GraphQL Java implementation which I used in code doesn’t do optimizations, caching or similar, you need to write code for it. That is why I said that we need to be aware that we are using implementation of GraphQL, since GraphQL is spec only. Maybe some implementation of GraphQL also add caching and optimizations.