

Whether you know it or not, your Java web application is most likely using a thread pool to handle incoming requests. This is an implementation detail that many overlook, but sooner or later you will need to understand how the pool is used, and how to correctly tune it for your application. This article aims to explain the threaded model, what a thread pool is, and what you need to do to correctly configure them.
Single Threaded
Let us start with some basics, and progress with the evolution of the threaded model. No matter which application server or framework you use, Tomcat, Dropwizard, Jetty, they all use the same fundamental approach. Buried deep inside the web server is a socket. This socket is listening for incoming TCP connections, and accepting them. Once accepted, data can be read from the newly established TCP connection, parsed, and turned into a HTTP request. This request is then handed off to the web application, to do with what it wants.
To provide an understanding of the role of threads, we won’t use an application server, instead we will build a simple server from scratch. This server mirrors what most application servers do under the hood. To start with, a single threaded web server may look like this:
ServerSocket listener = new ServerSocket(8080);
try {
while (true) {
Socket socket = listener.accept();
try {
handleRequest(socket);
} catch (IOException e) {
e.printStackTrace();
}
}
} finally {
listener.close();
}
This code creates a ServerSocket on port 8080, then in a tight loop the ServerSocket checks for new connections to accept. Once accepted the socket is passed to a handleRequest method. That method would typically read the HTTP request, do whatever process is needed, and write a response. In this simple example, handleRequest reads a single line, and returns a short HTTP response. It would be normal for handleRequest to do something more complex, such as reading from a database, or conducting some other kind of IO.
final static String response =
“HTTP/1.0 200 OK\r\n” +
“Content-type: text/plain\r\n” +
“\r\n” +
“Hello World\r\n”;
public static void handleRequest(Socket socket) throws IOException {
// Read the input stream, and return “200 OK”
try {
BufferedReader in = new BufferedReader(
new InputStreamReader(socket.getInputStream()));
log.info(in.readLine());
OutputStream out = socket.getOutputStream();
out.write(response.getBytes(StandardCharsets.UTF_8));
} finally {
socket.close();
}
}
As there is only a single thread handling all accepted sockets, each request must be fully handled, before accepting the next. In a real application it could be normal for the equivalent handleRequest method to take on the order of 100 milliseconds to return. If this was the case, the server would be limited to handling only 10 requests per second, one after the other.
Multi-threaded
Even though handleRequest may be blocked on IO, the CPU is free to handle more requests. With a single threaded approach this is not possible. Thus this server can be improved to allow concurrent operations, via creating multiple threads:
public static class HandleRequestRunnable implements Runnable {
final Socket socket;
public HandleRequestRunnable(Socket socket) {
this.socket = socket;
}
public void run() {
try {
handleRequest(socket);
} catch (IOException e) {
e.printStackTrace();
}
}
}
ServerSocket listener = new ServerSocket(8080);
try {
while (true) {
Socket socket = listener.accept();
new Thread(new HandleRequestRunnable(socket)).start();
}
} finally {
listener.close();
}
Here, accept() is still called in a tight loop within a single thread, but once a TCP connection is accepted, and a socket available, a new thread is spawned. This spawned thread executes a HandleRequestRunnable, which simply calls the same handleRequest method from above.
Creating the new thread, now frees up the original accept() thread to handle more TCP connections, and allows the application to handle requests concurrently. This technique is referred to as a “thread per request”, and is the most popular approach taken. It is worth noting there are other approaches, such as the event driven asynchronous model NGINX and Node.js deploy, but they don’t use thread pools, and thus are out of scope for this article.
In the thread per request approach, creating a new thread (and later destroying it) can be expensive, as both the JVM and the OS needs to allocate resources. Additionally in the above implementation, the number of threads being created is unbounded. Being unbounded is very problematic, as it can quickly led to resource exhaustion.
Resource exhaustion
Each thread requires a certain amount of memory for the stack. On recent 64bit JVMs, the default stack size is 1024KB. If the server receives a flood of requests, or the handleRequest method becomes slow, the server may end up with huge number of concurrent threads. Thus to manage 1000 concurrent requests, the 1000 threads would consume 1GB of the JVM’s RAM just for thread’s stacks. In addition the code executing in each thread will be creating objects on the heap needed to process the request. This very quickly adds up, and can exceed the heap space assigned to the JVM, putting pressure on the garbage collector, causing thrashing and eventually leading to OutOfMemoryErrors.
Not only consuming RAM, the threads may use other finite resources, such as file handles, or database connections. Exceeding these may led to other types of errors or crashes. Thus to avoid exhausting resources it is important to avoid unbounded data structures.
Not a panacea, but the stack size issue can be somewhat mitigated by tuning the stack size with the -Xss flag. A smaller stack will reduce the per thread overhead, but potentially leads to StackOverflowErrors. Your mileage will vary, but for many applications the default 1024KB is excessive, and smaller 256KB or 512KB values might be more appropriate. The smallest value Java will allow is 160KB.
Thread pool
To avoid continuously creating new threads, and to bound the maximum number, a simple thread pool can be used. Simply put, the pool keeps track of all threads, creating new ones when needed up to an upper bound, and where possible reusing idle threads.
ServerSocket listener = new ServerSocket(8080);
ExecutorService executor = Executors.newFixedThreadPool(4);
try {
while (true) {
Socket socket = listener.accept();
executor.submit( new HandleRequestRunnable(socket) );
}
} finally {
listener.close();
}
Now, instead of directly creating threads, this code uses an ExecutorService, which submits work (in the term of Runnables) to be executed across a pool of threads. In this example a fixed thread pool of four threads is used to handle all incoming requests. This bounds the number of “in-flight” requests, and thus places bounds on the resource usage.
In addition to newFixedThreadPool, the Executors utility class also provides a newCachedThreadPool method. This suffers from the earlier unbounded number of threads, but whenever possible makes use of previously created but now idle threads. Typically this type of pool is useful for short-lived requests that do not block on external resources.
ThreadPoolExecutors can be constructed directly, allowing for its behaviour to be customised. For example, the min and max number of threads within the pool can be defined, as well as policies for when threads are created and destroyed. An example of this is shown shortly.
Work queue
In the fixed thread pool case, the observant reader may wonder what happens if all threads are busy, and a new request comes in. Well the ThreadPoolExecutor may use a queue to hold pending requests before a thread becomes available. The Executors.newFixedThreadPool by default use an unbounded LinkedList. Again this leads to the resource exhaustion problem, albeit much slower since each queued request is smaller than a full thread, and will typically not be use as many resources. However, in our examples, each queued request is holding a socket which (depending on OS) would be consuming a file handle. This is the kind of resource that the operating system will limit, so it may not be best to hold on to it unless needed. Therefore it also makes sense to bound the size of the work queue.
public static ExecutorService newBoundedFixedThreadPool(int nThreads, int capacity) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(capacity),
new ThreadPoolExecutor.DiscardPolicy());
}
public static void boundedThreadPoolServerSocket() throws IOException {
ServerSocket listener = new ServerSocket(8080);
ExecutorService executor = newBoundedFixedThreadPool(4, 16);
try {
while (true) {
Socket socket = listener.accept();
executor.submit( new HandleRequestRunnable(socket) );
}
} finally {
listener.close();
}
}
Again, we create a thread pool, but instead of using the Executors.newFixedThreadPool helper method, we create the ThreadPoolExecutor ourselves, passing a bounded LinkedBlockingQueue capped to 16 elements. Alternatively an ArrayBlockingQueue could have be used, which is an implementation of a bounded buffer.
If all threads are busy, and the queue fills up, what happens next is defined by the last argument to the ThreadPoolExecutor. In this example, a DiscardPolicy is used, which simply discards any work that would overflow the queue. There are other policies, such as the AbortPolicy which throws an exception, or the CallerRunsPolicy which executes the job on the caller’s thread. This CallerRunsPolicy provides a simple way to self limit the rate jobs can be added, however, it could be harmful, blocking a thread that should stay unblocked.
A good default policy is to Discard or Abort, which both drop the work. In these cases it would be easy to return a simple error to the client, such as a HTTP 503 “Service unavailable”. Some would argue that the queue size could just be increased, and then all work would eventually be run. However, users are unwilling to wait forever, and if fundamentally the rate at which work comes in, exceeds the rate it can be executed, then the queue will grow indefinitely. Instead the queue should only be used to smooth out bursts of requests, or handle short stalls in processing. In normal operation the queue should be empty.
How many threads?
Now we understand how to create a thread pool, the hard question is how many threads should be available? We have determined that the maximum number should be bounded to not cause resource exhaustion. This includes all types of resources, memory (stack and heap), open file handles, open TCP connections, the number of connections a remote database can handle, and any other finite resource. Conversely, if the threads are CPU bound instead of IO bound, then the number of physical cores should be considered finite, and perhaps no more than one thread per core should be created.
This all depends on the work the application is doing. A user should run load tests using various pool sizes, and a realistic mix of requests. Each time increasing their thread pool size until breaking point. This makes it possible to find the upper bound, for when resources are exhausted. In some cases it may be prudent to increase the number of available resources, for example making more RAM available to the JVM, or tuning the OS to allow for more file handles. However, at some point the theoretical upper bound will be reached, and should be noted, but this is not the end of the story.
Little’s Law
![]()
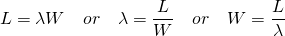
Queuing theory, in particular, Little’s Law, can be used to help understand the properties of the thread pool. In simple terms, Little’s Law describes the relationship between three variables; L the number of requests in-flight, λ the rate at which new requests arrive, and W the average time to handle the request. For example, if there are 10 requests arriving per second, and each request takes one second to process, there is an average of 10 request in-flight at any time. In our example, this maps to using 10 threads. If the time to process a single request is doubled, then the average in-flight requests also doubles to 20, and thus requires 20 threads.
Understanding the impact that execution time has on in-flight request is very important. It is common for some backend resource (such as a database) to stall, causing requests to take longer to process, quickly exhausting a thread pool. Therefore the theoretical upper bound may not be an appropriate limit for the pool size. Instead, a limit should be placed on execution time, and used in combination with the theoretical upper bound.
For example, let’s say the maximum in-flight requests that can be handled is 1000 before the JVM exceeds its memory allocation. If we budget for each request to take no longer than 30 seconds, we should expect in the worst case to handle no more than 33 ⅓ requests per second. However, if everything is working correctly, and requests take only 500ms to handle, the application can handle 2000 requests per second, on only 1000 threads. It may also be reasonable to specify that a queue can be used to smooth out short bursts of delay.
Why the hassle?
If the thread pool has too few threads, you run the risk of under utilising the resources, and turning users away unnecessarily. However, if too many threads are allowed, resource exhaustion occurs, which can be more damaging.
Not only can local resources be exhausted but it is possible to adversely impact others. Take for example, multiple applications querying the same backend database. Databases typically have a hard limit on the number of concurrent connections. If one misbehaving unbounded application consumes all these connections, it would block the others from accessing the database. Causing a widespread outage.
Even worse, a cascading failure could occur. Imagine an environment with multiple instances of a single application, behind a common load balancer. If one of the instances begins to run out of memory due to excessive in-flight requests, the JVM will spend more time garbage collecting, and less time handling the requests. That slow down, will reduce the capacity of that one instance, and force the other instances to handle a higher fraction of incoming requests. As they now handle more requests, with their unbounded thread pools, the same problem occurs. They run out of memory, and again begin aggressively garbage collecting. This vicious cycle cascades across all instances, until there is a systemic failure.
Far too often I’ve observed that load testing is not conducted, and an arbitrarily high number of threads is allowed. In the common case the application can happily process requests at the incoming rate using a small number of threads. If however, processing the requests depends on a remote service, and that service temporarily slows down, the impact of increasing W (the average processing time) can very quickly exhaust the pool. Because the application was never load tested at the maximum number, all the resource exhaustion issues outlined before are exhibited.
How many thread pools?
In microservice, or service oriented architectures (SOA), it is normal to access multiple remote backend services. This setup is particularly susceptible to failures, and thought should be made in gracefully dealing with them. If a remote service’s performance degrades, it can cause the thread pool to quickly hit its limit, and subsequent requests are dropped. However, not all requests may require this unhealthy backend, but since the thread pool is full these requests are needlessly dropped.
The failure of each backend can be isolated by providing backend specific thread pools. In this pattern, there is still a single request worker pool, but if the request needs to call a remote service, the work is transferred to that backend’s thread pool. This leaves the main request pool unburden by a single slow backend. Then only requests needing that particular backend pool are impacted when it malfunctions.
A final benefit of multiple thread pools, is it helps avoid a form of deadlock. If every available thread becomes blocked on a result of a yet to be processed request, then a deadlock occurs, and no thread is able to move forward. When using multiple pools, and having a good understanding of the work they execute, this issue can be somewhat mitigated.
Deadlines and other best practices
A common best practice is to ensure there is a deadline on all remote calls. That is, if the remote service does not respond within a reasonable time, the request is abandoned. The same technique can be used for work within the thread pool. Specifically, if the thread is processing one request for longer than a defined deadline, it should be terminated. Making room for a new request, and placing an upper bound on W. This may seem like a waste, but if the user (which might typically be a web browser) is waiting for a response, then after 30 seconds the browser might just give up anyway, or more likely the user becomes impatient and navigates away.
Failing fast, is another approach that can be taken when creating pools for backends. If the backend has failed, the thread pool will quickly fill up with request waiting to connect to the unresponsive backend. Instead, the backend can be flagged as unhealthy, all subsequent requests could fail instantly instead of needlessly waiting. Note however, that a mechanism is needed to determine when the backend has become healthy again.
Finally, if a request will need to call multiple backends independently, it should be possible to call them in parallel, instead of sequentially. This would reduce the wait time, at the cost of increased threads.
Luckily, there is a great library, hystrix, which packages many of these best practices and exposes them in a simple and safe way.
Conclusion
Hopefully this article has improved your understanding of thread pools. By understanding the application’s needs, and using a combination of the maximum thread count, and the average response time, an appropriate thread pool can be determined. Not only will this avoid cascading failures, but help plan and provision your service.
Even though your application may not explicitly use a thread pool, they are implicitly used by your application server or higher level abstraction. Tomcat, JBoss, Undertow, Dropwizard all provides multiple tunables to their thread pools (the pool which your servlet is executed).
Like what you read, find more articles like this on bramp.net, or follow @TheBramp.


Author: Andrew Brampton
Andrew Brampton started his career as a researcher, working on content distribution networks, peer to peer, and high performance networking. He left the academic world to work on real problems. Cutting his teeth at various small companies typically deploying Java software stacks. Currently he is a Site Reliability Engineer at Google, the team that keeps Google up and running at scale.
He is a prolific contributor to open source, as seen by his GitHub profile, and loves learning about new technologies that aid in high performance distributed computing. Follow him on Twitter, or subscribe to his blog.